Format builder
The Format builder is a main part of Squey that is fully dedicated to the creation and management of Formats to process text files.
Creating a Format can sometimes require some patience and skills but once the Format is ready and properly working, it can be used for a long time. It is usually quickly amortized.
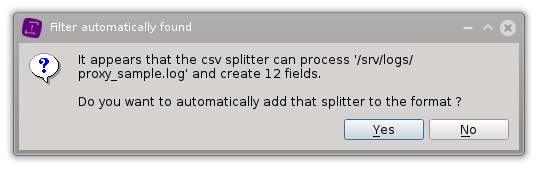
The format builder is able to automatically detect the most commonly used data types. It can for example automatically detect CSV files with the proper separator and quoting characters, a potential header and use it as axes name, but also all the supported columns types !
To begin, try to load a sample of your data file as follow :
Create a format > File > Local file (or any other input plugin type that is supported)
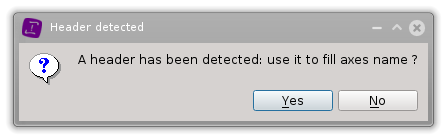
If a header is detected, you will be prompted to use it to automatically fill axes names
If you need to further tweak your format, you can at any time try to detect the axes types again :

Note
Specifying 0 row(s) will perform the autodetection on the whole input data.
Axes properties
Types
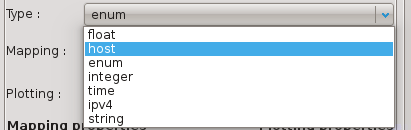
Available axes types are the following:
string
number_int32
number_uint32
number_float
time
ipv4
ipv6
mac_address
The type is tightly related to the way the data is internally stored in order to optimize the user operations.
Note
- For number_int32 / number_uint32, the parsing format can be defined as such :
Octable : %o
Hexadecimal : %x
Mappings
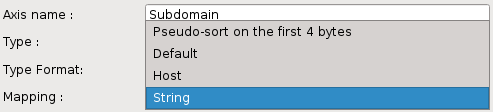
Non default mappings are available for the following axes types:
time: #. Week #. 24 hours
mac_address #. Uniform vendor - Uniform NIC #. Uniform vendor - Linear NIC #. Linear vendor - Uniform NIC #. Linear MAC
(all): #. Pseudo-sort on the first four bytes #. String #. Host
More explanation on the ‘String’ mapping : the algorithm is ordering values using four successive levels of clustering in order to minimize the level of zoom needed to separate the values.
Logarithm of the string length: visible from the global parallel coordinates view.
String length: makes a wider values repartition.
First character value: ensure an alphabetical separation at this level.
Sum of the remaining characters : provides a maximal entropy.
Scalings
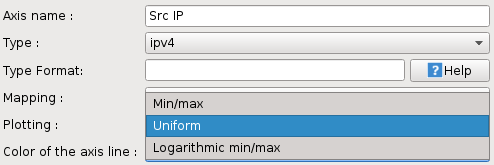
The available scalings are the following:
number_uint32 #. Port : Privileged ports (< 1024) are located on the lower half of the axis and other ports on the higher half
(all) #. Min/max : The values are linearly plotted against the whole axis using the min and max values as extremes. #. Logarithmic min/max : Same as Min/max except that the values are plotted using a logarithmic scale. #. Uniform : The values are evenly distributed along the axis in a sorted way
Additional parameters
Axes also have additional parameters such as a line/title color and a group.
Splitters
Splitter are intended to break fields into several sub-fields. They can be nested no matter what their types are in order to produce powerful processing workflows.
CSV splitter
This splitter allows basic control over the dividing of the lines using a unique character as field separator.

The parameters are the following:
Field separator
Quote character
Number of columns
Fixing the number of columns is done using the spinbox buttons.
RegExp splitter
This splitter allows maximum control over the dividing of the lines yet it may be slightly more complex to handle.
Warning
Albeit more powerful, this splitter is also slower than the CSV splitter. As such, it is adviced to use nested CSV splitters whenever possible to avoid slowing down the import process.
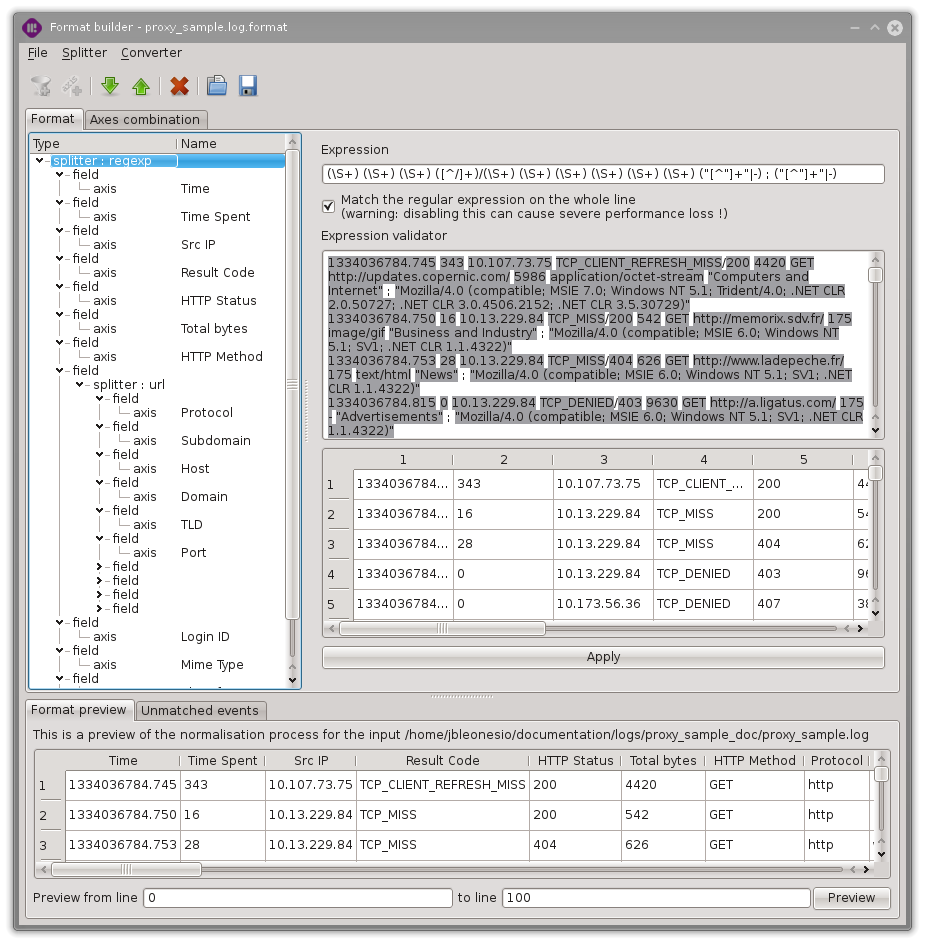
Quick guide:
+(matching_pattern)+ captures a group with the matching pattern
d+ matches a number
S+ matches any string without space (space or tab or so on)
[^;,]+ matches any character but semi-colons or comas
Ease the construction of the regular expression with the expression validator :
Put a catchall group +(.*)+ in the ‘Expression’ fields in order to match all the events.
Import a log sample using the ‘File’ menu.
Add your capturing groups in front of the catchall group in order to take use of the expression validator (matching events will then be highlighted, errors will disable the highlight).
Remove the final catchall group.
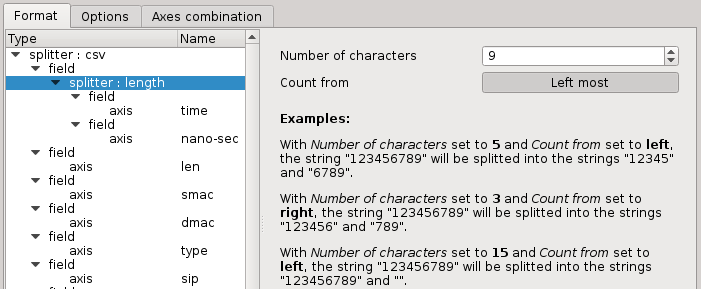
Length splitter
This splitter is intended to split a field at any arbitrary position from the left most or right most character. Like all other splitters, it can be nested to allow recursive splitting.
Duplicate splitter
The duplicate splitter is usefull to keep a copy of a field before breaking it.

The only parameter to be specified is the number of duplications which represents the total amount of identic fields being created.
Key Value splitter
This splitter addresses the following problem: it is very hard to deal with logs that have part of the lines containing strings representing a list of Key=Value pairs, especially if the structure of the line is not stable (some new keys can appear on very specific lines; the order of the keys can change from one line to another).
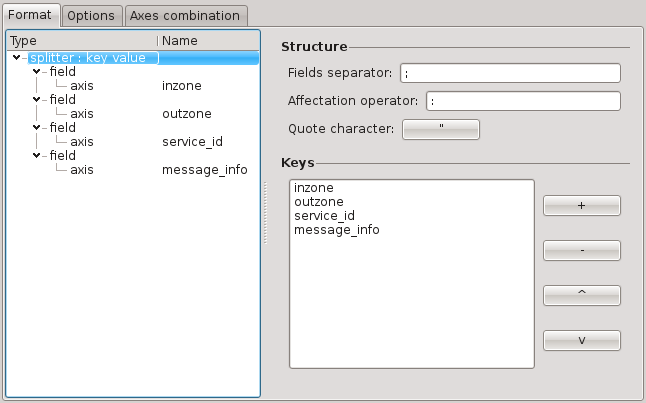
The following options can be specified:
Fields separator (can be several characters, useful to remove spaces)
Affectation operator (can be several characters, useful to remove spaces)
Quote character
inzone: Internal; outzone: External; service_id: ftp
service_id: FIBMGR; inzone: Local; outzone: Internal; message_info: Implied rule
outzone: External; inzone: Internal; service_id: https
message_info: Address spoofing
Fields separator and affectation operator can be escaped if the value is enclosed by quote characters. Quote characters are then discarded in order to improve mapping and sorting results.
login="John", pwd="K5Kh,DFR", uid="5489", gid="8147"
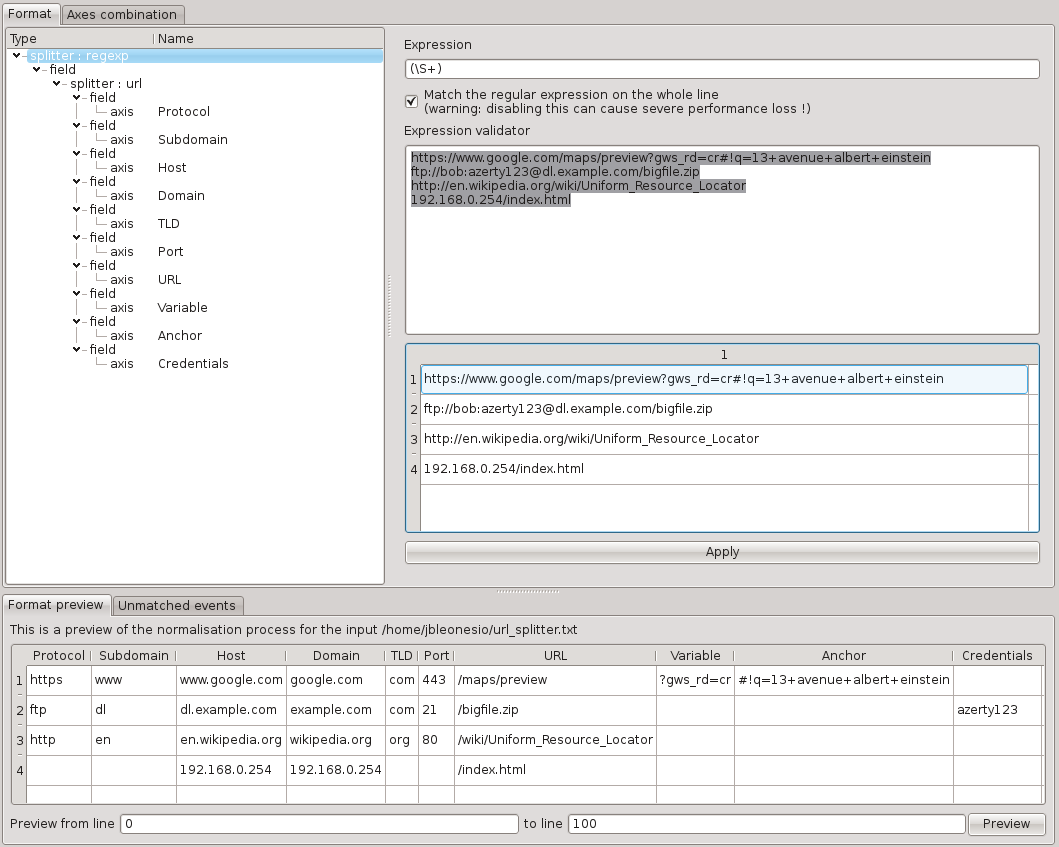
URL splitter
The URL splitter breaks any URL into the following fields:
Protocol
Subdomain
Host
Domain
TLD
Port
URL
Variable
Anchor
Credentials
Note
At the present time, removing some axes of the url splitter could only be achieved by editing by hand the according format file.
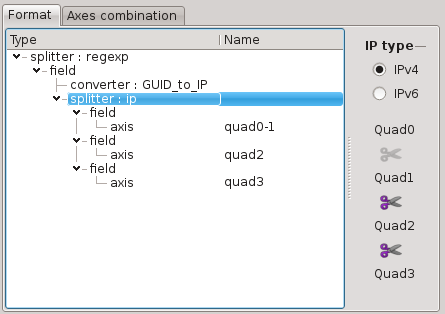
IP splitter
The IP splitter is usefull to break the quads/groups of an IP address in order to reveal the entropy of subnetworks.
DNS FQDN splitter
The DNS Full Qualified Domain Name (FQDN) splitter is useful to extract different parts of a FQDN resulting from a DNS query.
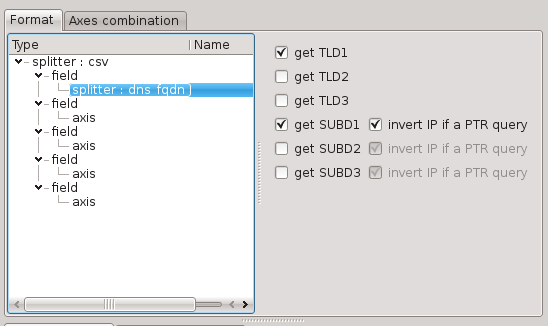
The possible parts are:
the last domain (TLD1): ‘com’ in ‘www.en.example.com’
the last two domains (TLD2): ‘example.com’ in ‘www.en.example.com’
the last three domains (TLD3): ‘en.example.com’ in ‘www.en.example.com’
all but the last domain (SUBD1): ‘www.en.example’ in ‘www.en.example.com’
all but the last two domains (SUBD2): ‘www.en’ in ‘www.en.example.com’
all but the last three domains (SUBD3): ‘www’ in ‘www.en.example.com’
If a part is not present in the parsed FQDN, the corresponding field will be empty.
When the parsed FQDN is the result of DNS PTR query (‘inverted IPv4’.in-addr.arpa or ‘inverted IPv6’.ip6.arpa), the resulting fields have a special behaviour:
for the ‘TLD3’ part, the corresponding field is empty;
for the ‘SUBD’ parts, the corresponding fields contain the whole IP address; the IP address can also be inverted to be in the conventional order (‘192.168.1.1’ instead of ‘1.1.168.192’).
MAC address splitter
The MAC address splitter breaks any MAC address into the following fields:
Vendor part
Device part
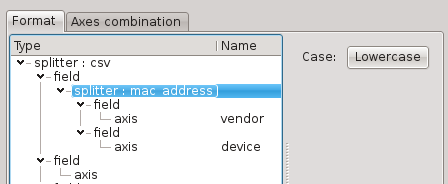
MAC addresses have three official representations:
01:23:45:67:89:ab
01-23-45-67-89-ab
0123.4567.89ab
The fields are uniformized using the first one. For convenience, the result can be automatically uppercased or lowercased.
Converters
Substitution converter
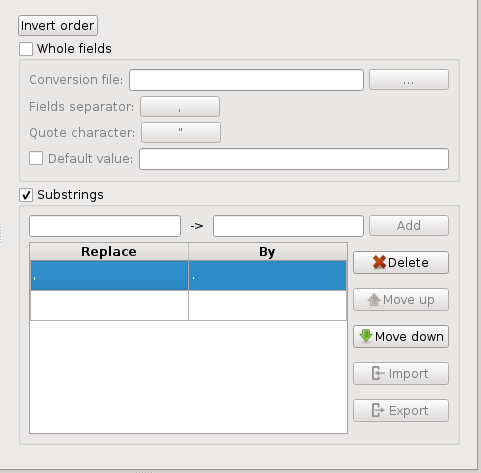
This converter is able to operate in a combination of the following modes :
whole fields : takes a two-columns CSV file as input and replaces each occurrence of a field contained in the first column by its value in the second column.
substrings : replace several substrings
In the first mode, it is possible to specify both the separator/quote characters, and a “default value” option is available to specify the value to give to the field in case there is no match in the CSV file. This could be useful to create a column of security ranking based on the values in a list, for example a list of domains known to be malicious:
"maliciousdomain1.com", "0.1"
"maliciousdomain2.com", "0.5"
"maliciousdomain3.com", "0.2"
"maliciousdomain4.com", "0.3"
"maliciousdomain5.com", "0.2"
Default value: “1”
The second mode comes in handy to slightly tweak values, for instance changing numbers locale :
12 345,67
12345.67
Struct converter
The struct converter allows to identify structural patterns by removing all the alphanumeric characters of a field.
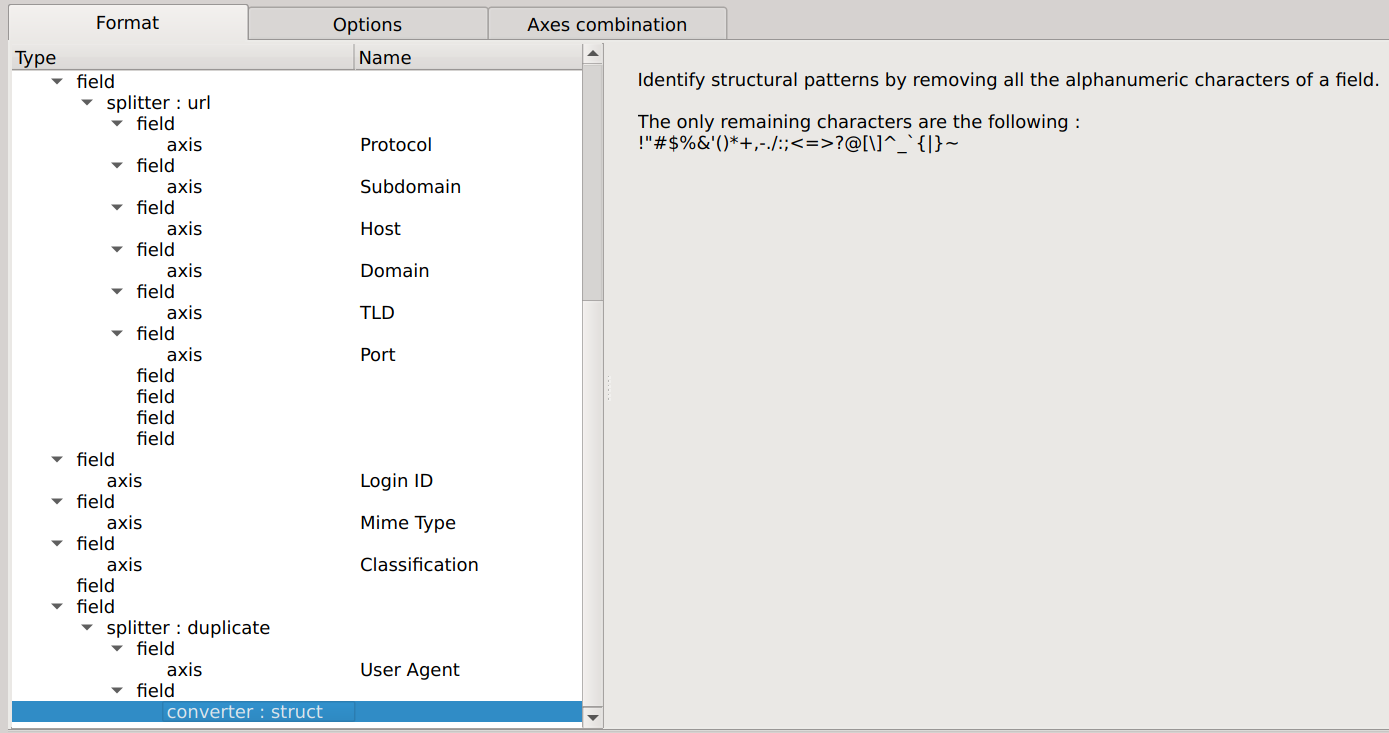
Used on the following URL :
http://mt0.google.com/vt/ft?lyrs=h%40175310222&las=a,b,c,d,e,f&z=8&gl=fr&hl=fr&xc=1&opts=z&callback=_xdc_._1oh0ygtk0b
it gives the following result :
://..//?=%&=,,,,,&=&=&=&=&=&=\_\_._
Note
This converter is not resticted to the entire row : it can be used on any field (can be used in conjuction with the duplicate splitter to keep the origin field). It is also not limited to the first 30 characters…
GUID to IP converter
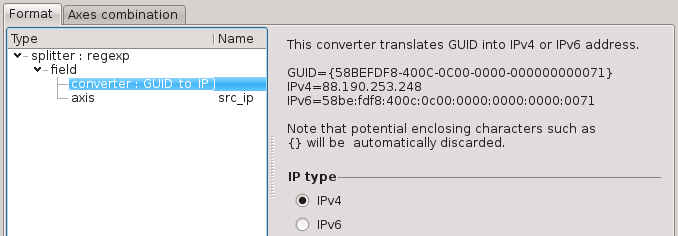
This converter translates GUID identifiers into IPv4 or IPv6 addresses. It is useful as some products (such as Microsoft Threat Management Gateway) are storing IP addresses as GUID.
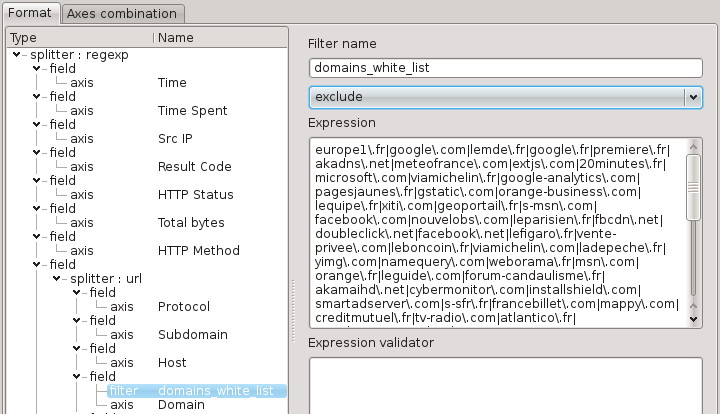
Filters
Filters are intended to reduce the number of events contained in the source. A filter is composed by a name, one or more regular expressions (one by line) and filtering property (include/exclude).
Tree panel
The tree panel represents the format’s workflow, the sequence of elements composing the format.
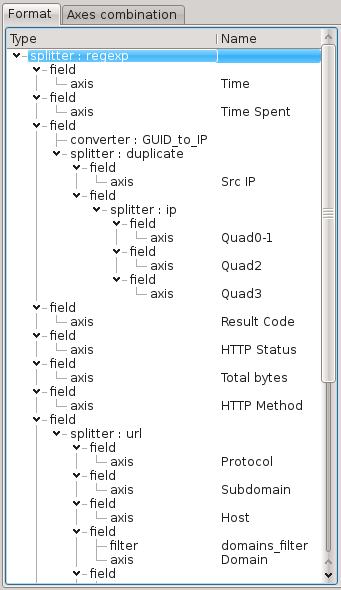
Fields must contain:
Zero or one splitter
Zero or several filters
Zero or several converters
Zero or one axis
At least one splitter or one axis
Clicking on an element displays its properties.
Format preview
The format preview gives a listing preview of the format currently applied on the log sample.
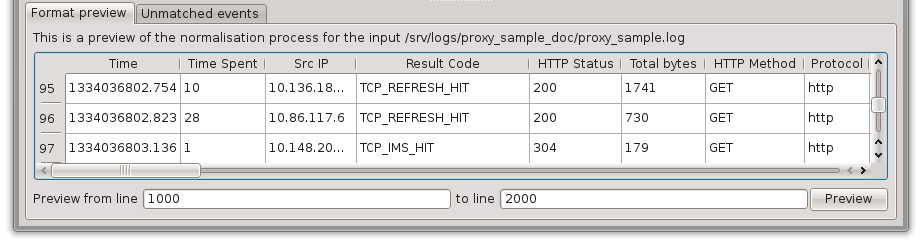
The lines to be previewed can be changed and validated using the Preview button. This can be useful to skip the parts of a sample log file which are not representative enough.
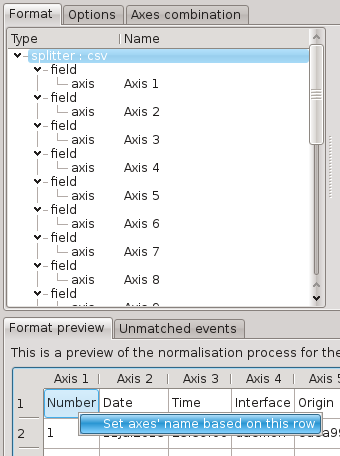
It can also be used to automatically setting all the axes’ name by right-clicking on a row and choosing “Set axes’ name based on this row”
Unmatched events
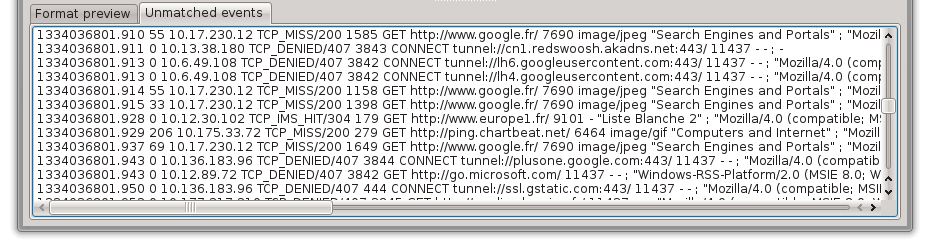
This panel lists all the lines that don’t match the current format. This can be caused by errors in the used splitters or simply because of filters.
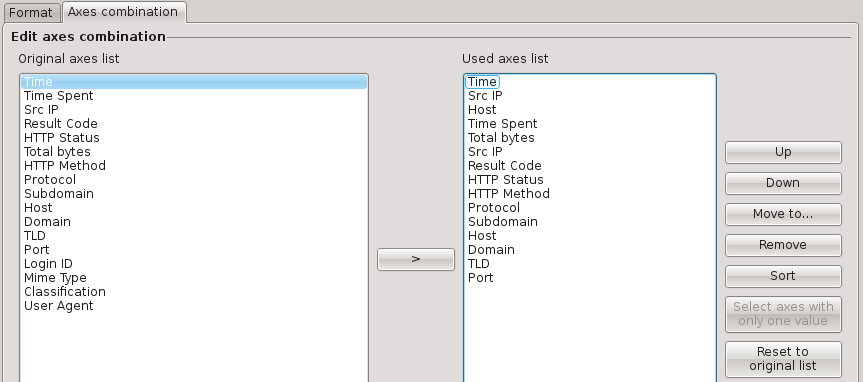
Axes combination
Note
Due to a current limitation, manually resetting the axes combination is needed when changing the number of created axes to avoid axes mismatches.
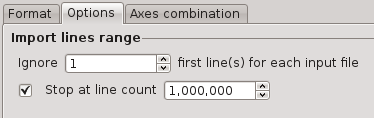
Other options
Ignoring CSV headers or limiting the number of imported files can be done using the import lines range options.